728x90
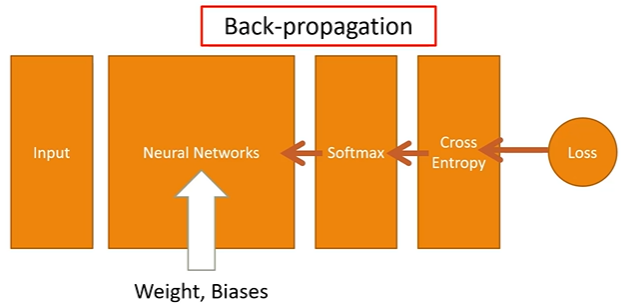
Back-propagation이란?
Feed-Forward의 결과로 얻은 Loss function은 결국 w와 b의 함수로 이루어졌기 때문에 출력부분부터 시작해서 입력쪽으로(역방향으로) 순차적으로 loss function에 대한 편미분을 구하고, 얻은 편미분 값을 이용해서 w와 b의 값을 갱신시킨다.
모든 훈련데이터에 대해서 이 작업을 반복적으로 수행하게 되면, 결국에는 훈련데이터에 최적화된 w와 b값들을 얻을 수 있다. 즉, 역전파(Back-propagation)란 용어는 출력부터 반대방향으로 순차적으로 편미분을 수행해가면서 w와 b값들을 갱신시킨다는 의미이다. 이는 chain Rule을 이용해서 계산할 수 있다.

그렇다면 Chain Rule이란 무엇일까?
chain rule은 합성함수에서 발생하는 미분의 연쇄법칙이다. 몇가지의 예시를 보면서 이해하면 될거같다.
예시1) 입력값, 중간값이 모두 1개일때

예시2) 중간값이 u1, u2 두개일때

예시3) 입력값이 x1, x2 두개이고 중간값이 u1,u2 두개일때
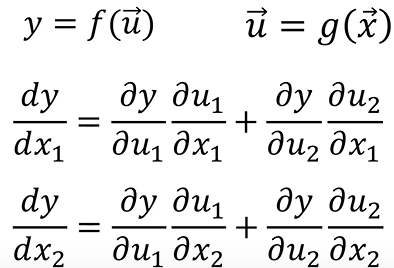
이와 같이 입력값과 중간값이 스칼라가 아닌 벡터가 될 때, 미분값은 굉장히 복잡해진다. 따라서 수식을 이용해서 미분한 결과를 보기 편하게 나타낸 것이 바로 Gradient와 Jacobian이다.
Gradient: 스칼라를 입력에 대해 미분한 것을 말한다.

Jacobian: 여러개의 출력물이 있을 때 그 출력물을 입력에 대해 각각 미분한 것을 말한다. gradient 여러개의 모임이라고 보면 된다.

728x90
'Deep Learning' 카테고리의 다른 글
| [DL] 하이퍼파라미터 튜닝 정리 (0) | 2022.05.01 |
|---|---|
| [DL] Gradient Descent의 문제점과 여러가지 Optimzer (0) | 2022.04.17 |
| [DL] ANN 활성함수 (Activation function) 종류 (0) | 2022.04.17 |
| [DL] Pytorch을 이용한 모델생성 (0) | 2022.03.28 |
| [DL] 인공신경망에 관련된 개념 정리 (0) | 2022.03.20 |




댓글