신경망에서는 노드에 들어오는 값들에 대해 곧바로 다음 레이어로 전달하지 않고 활성화 함수를 통과시킨 후 전달한다. 활성화 함수(activation function)는 입력 신호의 총합을 출력 신호로 변환하는 함수로, 입력 받은 신호를 얼마나 출력할지 결정하고 네트워크에 층을 쌓아 비선형성을 표현할 수 있도록 해준다.
1. step function
함수의 형태는 0보다 작은경우 0, 0보다 큰경우 1이 되며, 미분했을 때 값이 0이 되므로, 인공신경망의 활성함수로 사용하기에는 부적합하다(가중치값들을 찾기 힘들다).


2. sigmoid
보라색부분이 f(x)에 해당한다. f(x)는 입력값 x에 해당하는 출력값이 0~1사이가 되는 특징이 있다. 미분했을 때는 초록색부분의형태가 되는데, sigmoid를 활성함수로 사용하는 경우 심층신경망일 때 오차율계산이 어렵다는 문제가 발생한다.(미분값이 너무작아서 곱해질경우 0에 수렴하게 된다). 미분값이 사라진다는 뜻으로 "vanishing gradient problem"이라고 한다.


3. tanh
검정색 부분이 f(x)에 해당한다. tanh는 sigmoid와 매우 유사하다. 차이점은 sigmoid의 출력범위가 0~1사이인 반면 tanh의 출력범위는 -1~1사이이다. 미분했을 때는 빨간색 그래프의 형태를 띄게 된다. sigmoid와 비교했을 때 최대 미분계수가 1로, 4배가 큰 것을 확인할 수 있다. sigmoid보다는 양호하지만 은닉층의 깊이가 깊다면 sigmoid와 마찬가지로 vanishing gradient problem이 발생한다.
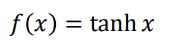

4. ReLU
초록색 부분이 f(x)이다. sigmoid와 tanh가 갖는 gradient vanishing문제를 해결하기 위한 함수이다. 입력값 x가 0보다 크다면 미분값이 1로 일정하게 되므로, Back-propagation과정에서 미분값이 0에 가까워지는 현상을 막을 수 있다. 구현이 매우 간단하기도 해서 인공신경망 학습에 대표적으로 쓰이는 활성함수이다.


'Deep Learning' 카테고리의 다른 글
| [DL] 하이퍼파라미터 튜닝 정리 (0) | 2022.05.01 |
|---|---|
| [DL] Gradient Descent의 문제점과 여러가지 Optimzer (0) | 2022.04.17 |
| [DL] Back-propagation과 Chain Rule (1) | 2022.04.04 |
| [DL] Pytorch을 이용한 모델생성 (0) | 2022.03.28 |
| [DL] 인공신경망에 관련된 개념 정리 (0) | 2022.03.20 |



댓글